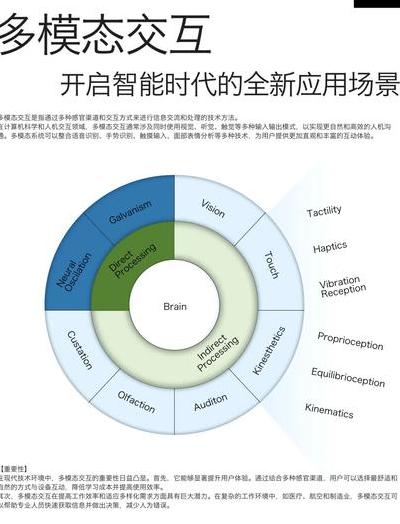
多模态交互技术正成为人工智能领域非常具有变革性的发展方向之一,它是一种可以同时处理语音、视觉、触觉等多种输入方式的系统,正在完全改变我们与机器互动的方式,多模态技术的应用场景在不断扩大,范围涵盖从智能手机到智能家居,从虚拟助手到自动驾驶。
多模态交互的技术基础
多模态交互的核心是让AI系统具备像人类一样的能力,它要能同时理解来自不同感官的信息,还要能整合这些信息,实现这一目标需要深度神经网络拥有跨模态的特征提取能力,也需要其拥有跨模态的融合能力,架构的出现为达成这一目标提供了可能性,它可以处理不同模态的序列数据。
当前最先进的多模态模型如GPT-4V,已具备一种能力,可在统一表征空间里对齐视觉、语音和文本信息,凭借该能力,系统能理解“红色圆形按钮”这类视觉描述,还能将其与相应操作指令关联起来。
主流多模态交互场景
在智能家居领域,多模态交互能使用户控制其系统,用户可以借助语音来实现操作,也能通过手势来实现操作,甚至凭借眼神来实现这一操作。例如,当用户说出“调亮灯光”,并且指向特定区域时,系统就能精准理解用户的意图。这种交互方式非常自然,极大地降低了技术使用门槛。
在教育领域,多模态AI辅导系统能观察学生表情,能观察学生语音语调,进而判断他们的理解程度,还能判断他们的注意力状态。当检测到学生困惑时,系统会自动调整讲解方式,或者提供可视化辅助,通过这些来实现真正的个性化教学。
技术实现的关键挑战
多模态对齐是极难攻克的技术难题,不同模态的数据在特征空间里的表示差异极大,要建立它们之间的语义关联,需进行复杂的建模,比如要将“鸟鸣声”的音频特征与“小鸟”的视觉特征精准匹配,就得开展大量的跨模态预训练。
另一个挑战是对实时性有要求,多模态交互常常需要即时做出响应,这对模型的计算效率提出了很高的要求,研究人员正在研发各种轻量化技术,研究人员正在研发边缘计算方案,其目的是降低延迟,进而提升用户体验。
多模态大模型的进化
2023年有多模态大模型出现,比如、等,它们展现出统一处理文本、图像、视频的潜力,这些模型借助海量跨模态数据进行预训练,还掌握了不同模态之间的转换能力以及推理能力。
最新进展是具身多模态AI,这类系统有理解多模态输入的能力,还能借助机器人等物理实体与环境互动。比如,一个具身AI能靠视觉识别物体,凭借触觉判断材质,再结合语音指令完成抓取任务。
行业应用案例分析
医疗领域是多模态技术极为重要的应用场景,AI诊断系统能同时对医学影像展开分析,还能对病理报告进行分析,也能对患者描述予以分析,从而给出更准确的判断,例如在通过CT扫描发现肺部结节时,系统会自动检索相似病例,还会自动检索最新治疗方案。
在汽车行业中,多模态交互可使驾驶更安全、更便捷,驾驶员能通过自然语言、手势和视线与车载系统互动,且不用分散注意力操作触摸屏,系统能综合判断驾驶员状态、路况及车辆数据,从而提供智能驾驶建议。
未来发展趋势

神经形态计算持续发展,未来的多模态系统可能会更接近人类的感知方式,脉冲神经网络等新技术有望实现更高效的多模态信息处理,而且能大幅降低能耗。
另一个重要方向是情感计算,系统能够理解用户的显性指令,系统还可以凭借微表情、语音语调等线索感知情绪状态,系统能达成真正的情感智能交互,这会彻底改变人机关系的本质。
你认为多模态交互技术最早会在哪个领域引发颠覆性的变革是教育领域吗,还是医疗领域,亦或是娱乐领域,又或者我们会看到全新的应用场景出现吗,欢迎在评论区分享你的看法,也别忘了点赞这篇文章,还要分享这篇文章。









