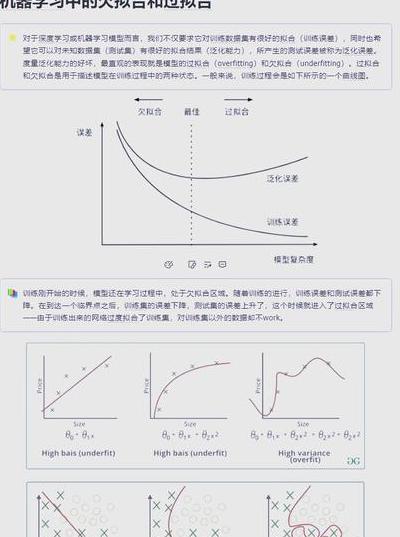
深度学习项目中,会出现过拟合现象。这就好比考试前靠死记硬背的学生,他们在训练集中成绩优异,然而一旦碰到新题目,真实水平就会显现出来。本文将用代码演示5种经实战验证的过拟合解决方案,其目的是让你的模型真正掌握“解题思路”,而非仅仅“背诵答案”。
正则化技术实战
L1/L2正则化仿佛给模型加上了具有限制作用的事物,在keras中,只需于Dense层增添参数:有一个密集层,其神经元数量是64,该密集层使用了L2正则化,正则化系数为0.01 。L1正则化能产生稀疏权重,这种权重适用于特征选择,L2正则化会让权重平缓衰减,它更适用于通用场景。
实验数据显示,在MNIST数据集中,有未进行正则化处理的模型,其测试准确率比训练集低8%,添加L2正则化后,这个差距缩小到了3%。要注意,正则化系数需通过网格搜索来确定,通常在0.001到0.1这个范围间尝试。
层应用诀窍
随机让一部分神经元“休息”,这种做法就是,在里实现只需要nn.(0.5)。关键是要区分训练和预测模式:model.train()时生效,model.eval()对于CNN,建议在全连接层采用0.5的丢弃率,在卷积层采用0.2到0.3的丢弃率,使用完后要及时关掉。
在IMDB影评分类任务中,通过运用,模型在验证集上的F1分数提高了12% 。需要特别注意的是,会使训练时间延长,原因是每次迭代训练的都是不同的子网络。
早停法实现技巧
早停法类似于那些懂得适时停止操作的交易员,在使用Keras来实现时,要先对回调进行定义。早停法,监测指标为“验证损失”,耐心值设为5 。参数用于决定容忍轮数,该参数通常被设定为总epoch的10%至20% 。它配合回调,可保存最佳权重。
在房价预测项目中,早停法在100轮训练时,于第63轮就停止了训练,它节省了37%的计算资源,并且其测试误差比完整训练降低了5% 。要记住,得先用验证集进行评估,只有这样做才能避免在测试集上作弊。
数据增强策略
对于图像数据,的模块提供20多种增强方法,其中建议组合使用旋转(±30°),建议组合使用水平翻转,建议组合使用亮度调节(0.8 – 1.2倍)等 。对于文本数据,可以使用同义词替换,也可以使用随机插入等库的方法 。
在CIFAR-10实验中,仅运用基础增强,可使的测试准确率提升9%,若再配合等高级技巧,还能再提高4%,需注意增强幅度要合理,否则过度增强会反而引入噪声。
模型简化方法论
通过model.()可以观察参数量,还能够使用可视化工具。常见的简化手段有这些,要减少LSTM隐藏单元数,也就是从256降到128,用全局平均池化替换全连接层,使用深度可分离卷积等 。
在工业缺陷检测项目当中,自定义 CNN 的层数从 8 层减少到了 5 层,参数量降低了 60%,不过测试准确率仅下降了 2%,而且推理速度提高了 3 倍。模型简化需要与剪枝、量化等技术相结合,如此才能发挥出最大效果。
集成学习方案
的可以快速获得多数人的投票,还有更高级的做法,即采用,在第一层使用异构模型,像RF、SVM以及NN,在第二层运用逻辑回归来进行元学习,要注意各基学习器需具有多样性。
在天池医疗文本分类比赛中,冠军方案采用了集成BERT、、的方式,将过拟合指标(即训练与测试的差异)从单模型的15%压缩到了7%。这种集成方法效果良好,但其计算成本较高,适用于关键任务场景。
在实际项目当中,你遇到的最难处理的过拟合案例是什么样的,你是怎样把它解决的,欢迎在评论区分享你的实战经历,记得点赞收藏这篇文章,方便随时查看!











